Das AMMOD-Team der Computer Vision Group in Jena, welches für die Entwicklung der Bildverarbeitungsalgorithmen in Modul 2 (visuelles Monitoring) verantwortlich ist, hat eine erste Veröffentlichung ihrer aktuellen Arbeiten erzielt. Der Beitrag von Julia Böhlke, Dimitri Korsch, Paul Bodesheim und Joachim Denzler mit dem Titel „Lightweight Filtering of Noisy Web Data: Augmenting Fine-grained Datasets with Selected Internet Images“ wurde auf der 16th International Conference on Computer Vision Theory and Applications – VISAPP 2021 angenommen und kann dort im Rahmen eines 20-minütigen Vortrags der Fachgemeinschaft präsentiert werden.
Das Thema der Arbeit ist die zusätzliche Verwendung von Bildern aus dem Internet, um den Trainingsdatensatz für einen Klassifikator zu ergänzen. In den meisten Anwendungen spielt die Größe des Trainingsdatensatzes und damit die Anzahl von Beispielbildern für verschiedene Arten eine entscheidende Rolle, schließlich trägt eine große Stichprobe maßgeblich zur Erkennungsleistung bei der automatischen Bestimmung von Tierarten in Bildern bei.
Das Jenaer Team stellt in ihrer Arbeit effiziente Methoden vor, um störende Bilder herauszufiltern, die für das Trainieren eines Klassifikators keine Relevanz haben bzw. das Lernen negativ beeinflussen würden. Dazu zählen beispielsweise Duplikate oder nahezu identische Bilder (near duplicates), die eine Suchmaschine für verschiedene Klassen liefert. Wenn solche Bilder in verschiedenen Klassen auftreten, kann dies zu einer Verwirrung des Klassifikators führen, da eine eindeutige Zuordnung zu einer Klasse nicht möglich ist.Außerdem werden Bilder automatisch aus den Suchergebnissen herausgefiltert, die nicht das Tier selbst zeigen, sondern andere Inhalte aufweisen. Diese können entweder mit der Art in Verbindung stehen und dennoch keinen Beitrag für die visuelle Arterkennung mit Kamerafallenbildern liefern (wie Verbreitungskarten, wissenschaftliche Abbildungen, o.ä.) oder komplett aus einem anderen Bereich sein (Fahrzeuge, Personen, o.ä.).
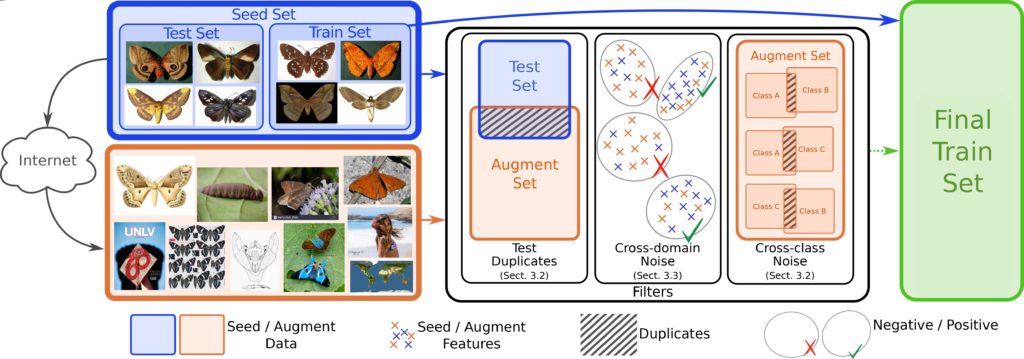
Die Hauptanwendung in dieser Arbeit ist die automatische Erkennung von mehreren hundert Nachtfalterarten, wobei initial für jede Art nur sehr wenige Beispielbilder vorlagen. Mit den zusätzlich erworbenen Trainingsdaten aus dem Internet und den vorgestellten Algorithmen kann die Erkennungsleistung deutlich verbessert werden. Ebenso wird gezeigt, dass die eingesetzten Filtermethoden eine Vielzahl von irrelevanten Bildern herausfiltern, was zu effizienteren Berechnungen hinsichtlich Trainingslaufzeit und Speicherplatz führt. Die Erkenntnisse aus dieser Arbeit leisten einen wichtigen Beitrag für die Arbeiten in Modul 2 zur visuellen Arterkennung in Bildern, insbesondere für die Entwicklung des Mottenscanners zur Beobachtung und automatischen Klassifizierung von Nachtfaltern.